
The Problem of Impact
How thinking like experimentalists could help us become more effective

TL;DR
When we talk about “impact,” we often mean different things: sometimes, impact means transforming one individual’s life, and sometimes it means reaching many people with smaller changes. Like in the design of experiments, our efforts at impact tend to face a tradeoff between effect size and scale. It's natural to want both, but this can lead to an incoherent strategy. Consider instead choosing your focus: either intensive, personalized work that transforms a few lives, or scalable systems that benefit many. Either path can be meaningful as long as you know where you are headed and design accordingly.
The Problem of Impact
I was going to call this post “Middle Age and the Problem of Impact.” But I figured that might hit a bit too close to home.
Like many readers, I presume, I am at a point where many of my peers have accomplished more in their careers than they ever imagined.
So the obvious next question is:
What’s next?
Usually, the answer is something like:
Impact.
But what does that actually mean?
While “impact” captures something important we all care about, the term can be imprecise. Breaking it down into more specific components—namely, effect size and scale—and using the language and methodology of experimental design might help us think more clearly about how to achieve our goals.
Why should we think in terms of experiments?
When starting this reframing exercise, it might be helpful to consider how researchers, at least in the social sciences, think about the ideal ways we can both enact and measure change in the world.
In social science, we are often interested in understanding cause-and-effect relationships. Oftentimes, these relationships are analyses of things that go on in the world independent of us as researchers. For instance, we might ask: what is the impact of innovation on firm performance? Or what is the impact of being in the center of a social network on the ability to generate novel ideas?
A challenge with answering whether this cause-and-effect relationship is real (e.g., whether the "if x then y" relationship is causal) is that there could be many other factors at play simultaneously. So we might confuse correlation, which means two things happening at the same time, with causation, where one causes the other.
To get a better handle on causality, researchers often run randomized controlled experiments.
What is an experiment, and how do you design one?
Let’s say you have a theory that X causes Y.
For instance, you believe a new teaching method helps students learn better and want to test if this is true. A natural starting point is comparing student performance before and after implementing the new method. However, the problem with this approach is that other factors could explain any improvement you observe.
Students might have grasped more foundational concepts by the time you implement the new method.
The assessment method itself might have changed.
Or students might have supplemented their learning with Khan Academy because the initial teaching was ineffective.
So a simple pre-post comparison cannot determine the causal effect.
A Randomized Controlled Trial helps deal with this problem of causal ambiguity. By randomly assigning some students to the new teaching method and others to the old one (e.g., flipping a coin to determine whether you get the intervention or not), you control for all these other confounding factors. The students and their experiences are identical except for the flip of the coin and this one change: the intervention, the new teaching method.
At the endpoint, you compare the two groups and their outcomes rather than comparing before and after. Did the new teaching method move the needle relative to the counterfactual? Both groups experience all the same external changes and are similar (or “balanced”) on both unobservable and observable traits, but only one receives the intervention.
The magic of randomization is that the two groups become essentially identical in every way that matters, except for the one thing you're testing.
This difference between the two groups in terms of the outcome is what tells you whether your theory, this innovation in teaching, actually translated into meaningful change, or whether you were fooling yourself.
Did your intervention have an effect?
Now imagine if you ran this experiment and measured outcomes. The table below (with simulated data) shows the results of a two-sample t-test comparing the control group (n=517, mean=49.81) to the treatment group (n=483, mean=54.99). The difference of 5.18 points between groups is statistically significant (p<0.01), providing strong evidence that the new teaching method caused improved learning outcomes.
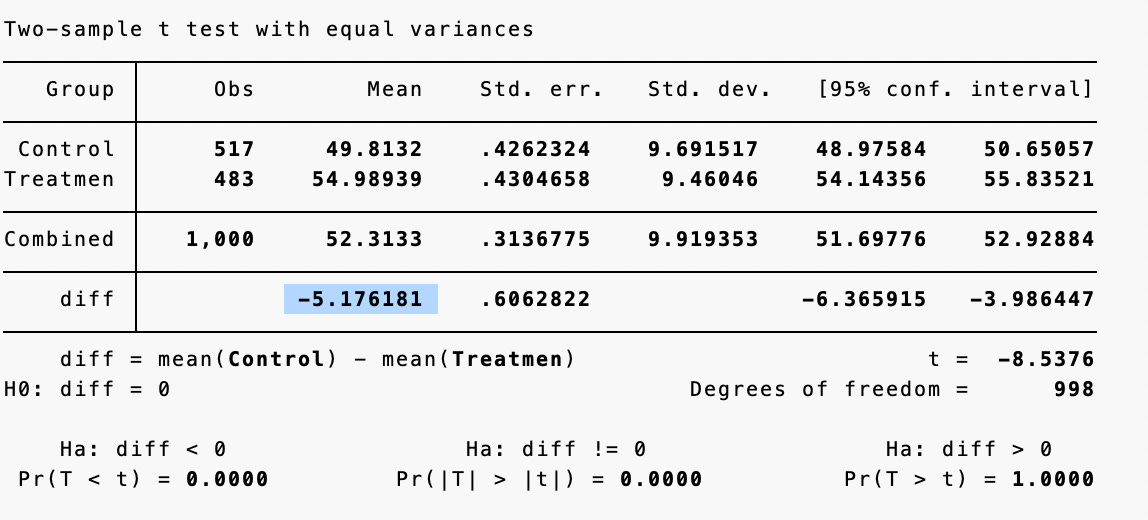
The graph below visually demonstrates this treatment effect as a rightward shift in the entire distribution of scores.
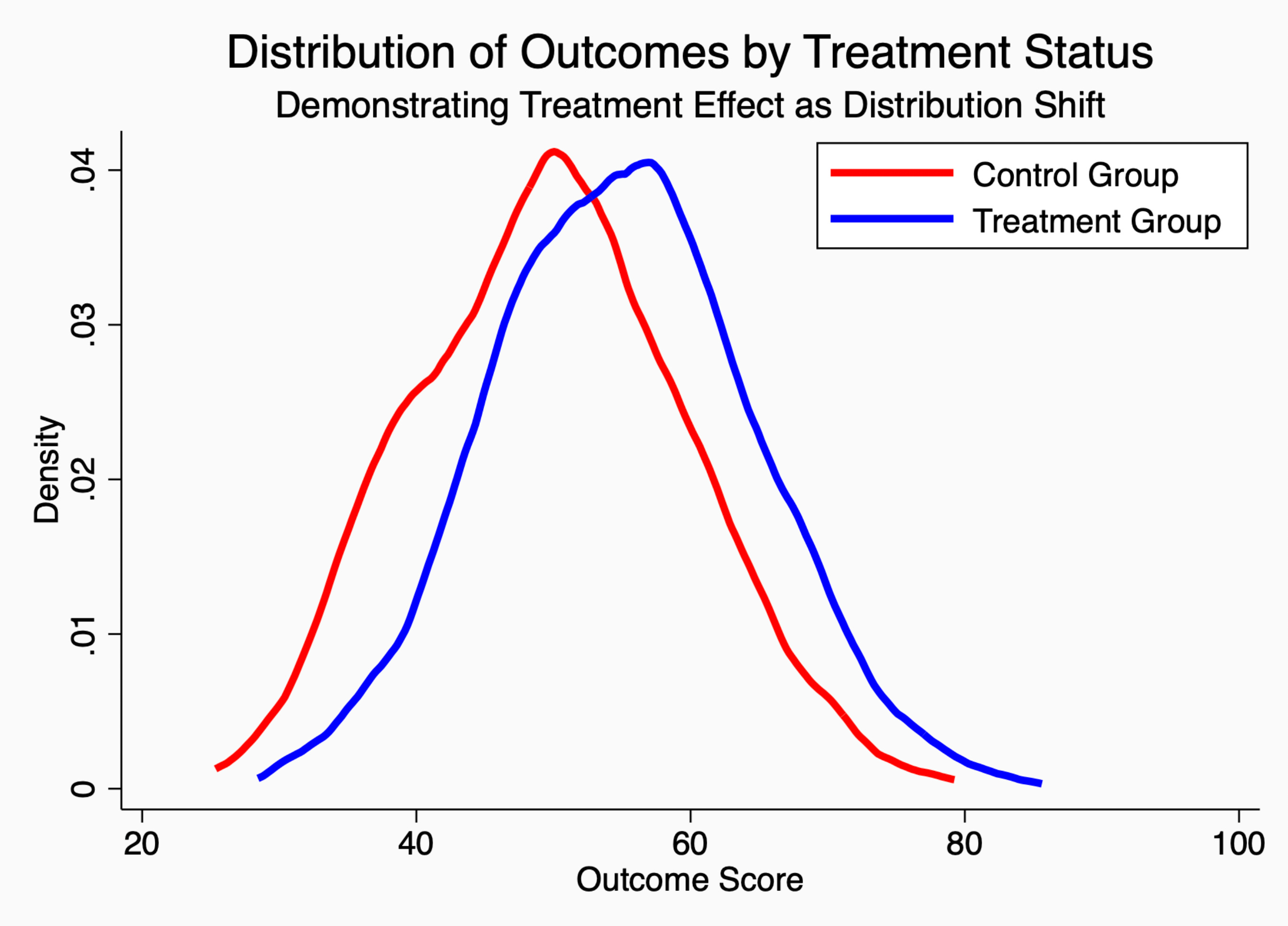
That difference between the treatment group and the control group is the quantity of interest for us: your treatment effect.
This is YOUR effect on these students’ learning.
The treatment effect is the causal impact of your intervention measured as the difference in outcomes between treated and control groups, but more fundamentally, it represents your ability to create meaningful change in the world: in this case, the improvement in students' learning that exists because of something you designed and implemented.
The effect size of 5.18 points could have been larger or smaller depending on countless factors: the specific design choices you made, the context in which you implemented the intervention, and the particular students involved, making this final number a unique outcome of all these factors.
The tradeoff between effect size and scale
Recently, I discussed an impressive field experiment at the National Bureau of Economic Research. The study tracked Ugandan high school students for 9 years after early-life entrepreneurship training (impressive!). The researchers found large, persistent treatment effects well into the ninth year. For anyone familiar with entrepreneurial training literature, these results stand in stark contrast to most programs, which typically show much smaller or null effects.
The size of the eventual treatment effect represents a deliberate design choice by the researchers: given a fixed budget constraint, they chose to invest heavily in teacher training and curriculum localization rather than spreading resources thin to reach more students with more generic content. This allocation decision reveals their theory of change, that deep, contextualized preparation of instructors would generate larger treatment effects than the typical approach of maximizing reach with off-the-shelf materials. This is a particular bet on the impact they wanted to have.
To me, the design of the intervention illustrates the fundamental trade-off between effect size and scale. The researchers chose to invest heavily in instructor training and localization, making their program harder to scale but dramatically more effective.
Scaling becomes difficult because localized content may not translate across contexts, high-quality instructor training takes substantial time and resources, and adapting materials to each new setting requires deep local knowledge. While they couldn't easily roll this out to thousands of schools, the students they did reach experienced real, lasting change. Meanwhile, generic programs can reach far more people but with smaller impacts. Interestingly, the total effect (effect size times the number of students reached) could be similar for both approaches.
The figure below captures the trade-off that we often face in designing interventions: maximize effect size or maximize scale.
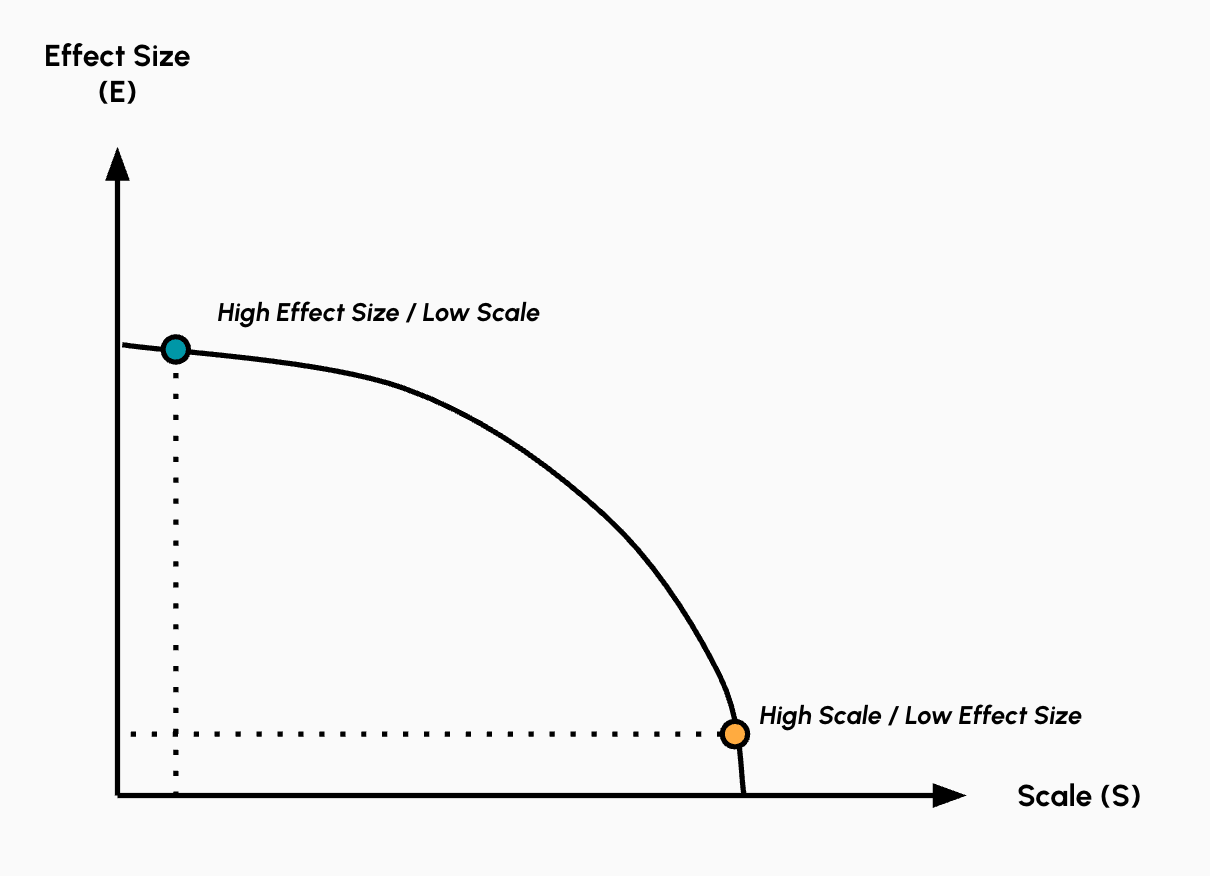
Of course, this framework presents a simplified model. In reality, some interventions do achieve both meaningful depth and broad scale, though these tend to be exceptions that often involve technological breakthroughs or fundamental innovations. The framework is most useful as a starting point for thinking about tradeoffs in our normal day-to-day actions, not as an absolute law.
Why does this trade-off exist?
At a glance, it seems like we should be able to take interventions designed for maximum effect size and simply replicate them broadly. But when you consider the logistical and technical constraints, as well as the statistical properties of experiments and when they actually produce effects, the trade-off between effect size and scale becomes less surprising.
Limited resources. The most obvious constraint is limited resources. Large-effect size interventions frequently rely on intensive inputs, both financial and human capital. You can see the difference in effects when you compare actively coaching and mentoring people with trained facilitators versus sending emails with high-level content on the same topics. This intensity of the first approach also enables better implementation, ensuring the intervention is delivered as designed. The counterpoint is, however, that with the money it takes to provide intensive support for a handful of people, you could reach thousands, even millions, with an email intervention.
Properly targeting your interventions. Beyond resources, targeting plays a critical role in determining effect size. A recent study in the American Economic Review found that targeting financing interventions to individuals with latent entrepreneurial ability nearly tripled the effect size, but acquiring such targeting information can be quite costly (Hussam, Rigol, and Roth 2022).
At scale, targeting precision is lost: eligibility criteria loosen, populations become more heterogeneous, and the average treatment effect gets diluted by less-engaged or marginally relevant participants.
Heterogeneous treatment effects. Relatedly, interventions affect people differently: what helps some may not help others, and can even cause harm. As interventions expand to include broader populations, heterogeneity in both baseline characteristics and contextual conditions increases. This leads to greater variance in outcomes and a flattening of average treatment effects.
Measuring the right outcome. Another crucial design choice is what to measure as your outcome. As your population expands, you need more generic measurements like wages, which not everyone might be optimizing or care about. But with a narrow, targeted population, your measurement can align closely with what participants actually value, creating a tighter coupling between treatment and meaningful outcomes. Similarly, more generic outcomes and the ability to collect data on them may introduce noise that makes your effect hard to detect, especially if it's small.
Feedback loops and experimentation. Finally, rarely is intervention design a one-time exercise; you're engaged in ongoing experimentation where each intervention generates learning that shapes your next iteration, making it crucial to think through how your measurement choices and observed outcomes will inform future design decisions.1
Designing a Path To Impact
Just like in field experiments, a strategy is often premised on first finding a position on the curve, and then deciding how to allocate resources to move incrementally closer to that position.
Indeed, this strategic positioning between effect size and scale parallels classic business trade-offs: differentiation versus cost leadership (Porter), specialization versus generalism (Hannan and Freeman), or, in statistical modeling terms, the bias-variance tradeoff.
Trying to maximize both effect size and scale simultaneously can create tensions that make it harder to excel at either. It’s like a coffee shop trying to be both a cozy neighborhood spot and a chain: it's plausible but challenging.
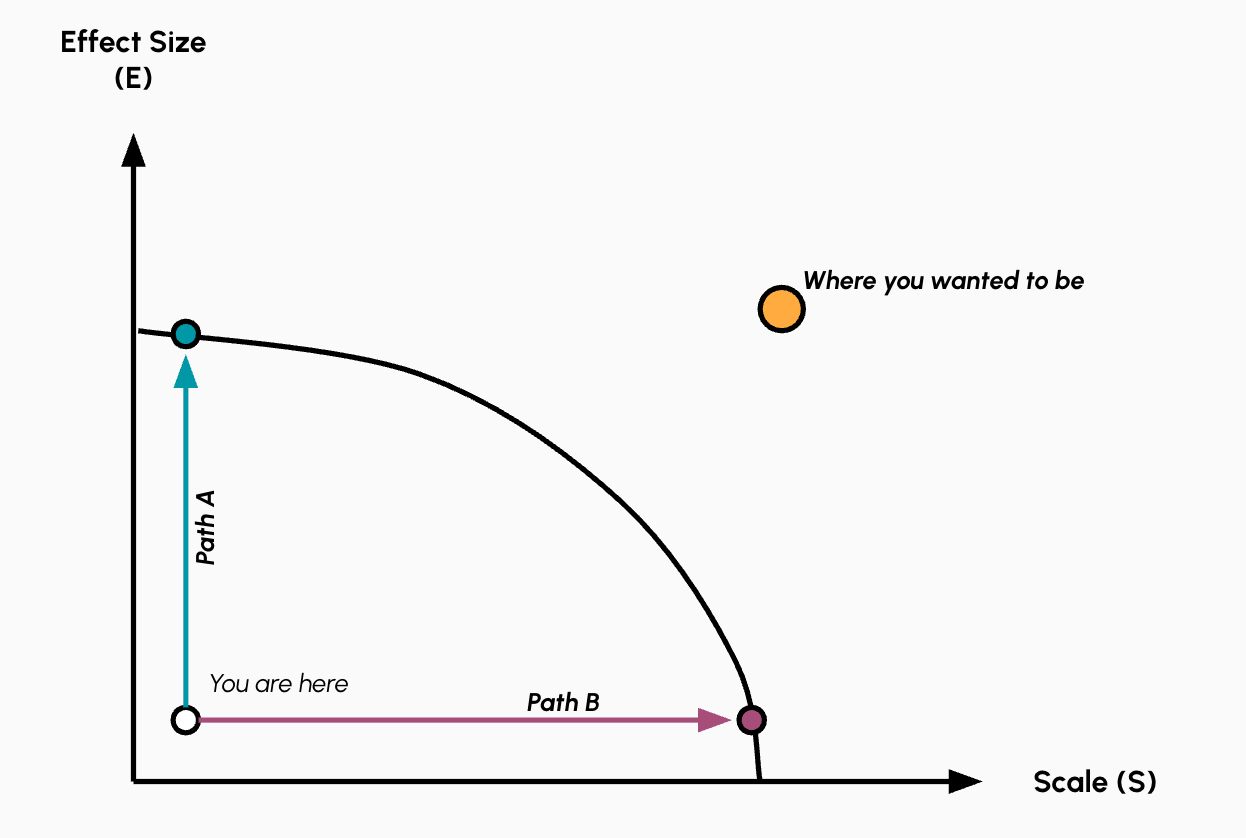
So you have to pick a point and move toward it.
If you've decided to go for high effect size (Path A), you will need to target precisely, tailor your approach, and be relentless in solving edge cases to figure out how to deliver impact for the few people you're trying to help. By the time you have impact, your “intervention” will be bespoke and narrow, and most of what you've done might be hard to generalize and even invisible to outsiders.
On the other hand, if you decide to go for high scale (Path B), you need to build a completely different kind of infrastructure, one that focuses on distribution, delegation, and generality, with the ability to operate without your involvement in making people's lives better.
Strategic Incoherence and the Bias Towards Scale
As such, the desire for “impact” often conceals a fundamental misunderstanding of the trade-off discussed above: wanting both a large effect size and a broad scale simultaneously is rarely possible.
This pursuit might sometimes reflect our natural desire for visible impact. Scale provides tangible evidence of our work, which is understandably appealing even when smaller-scale work might be more transformative.
So, our bias toward scale arises not because scale necessarily represents the most effective path to change (though it can be for some problems), but because it produces the most visible outcomes.
It satisfies our innate need for external validation.

However, failing to recognize that effect size can naturally decrease as interventions expand, and prioritizing what is visible over what is effective, can be self-defeating.
So is there a way out of this dilemma?
One approach is to start at one place, say, a highly specific solution for a narrow group, solve that really well, and then generalize.
This is a common strategy for startup founders, something Paul Graham has written about: start with things that don't scale but solve problems, then slowly expand while accepting that generalization will dilute effectiveness.
Alternatively, we can start broadly and then narrow down. This is like a foundation model for generative AI that helps lots of people a little bit, but no one incredibly well, then gradually, a company can add complexity through fine-tuning or RAG systems to increase accuracy for them at the expense of scale and generality.
Principles for Designing Interventions
Given the strategic positioning choice between effect size and scale, and understanding why we might become biased toward scaling, we probably should turn to a practical question: how do we design interventions that move the needle?
Design a Strong Intervention
One trick I now use in designing field experiments is to assume that most systems are in equilibrium, held together by economic, sociological, and psychological forces such as incentives, norms, and habits. These forces generate the stable patterns that keep the world turning (albeit dysfunctionally at times).
Any intervention aiming to change behavior must fight this equilibrium, and lighter-touch interventions like emails or nudges can work, but they often need to be especially well-designed or well-timed to overcome these existing forces.
To truly make a difference, we need to first understand the equilibrium and then design interventions with the right force to shift it.
Find the Invisible Zeros
One insight from Michael Kremer's O-Ring theory (named after the faulty O-Ring on the Challenger) is that complex processes often fail due to hidden bottlenecks that cause performance to drop to zero. These hidden bottlenecks destroy the value of everything else.
These zeros hide in different places depending on the problem you are trying to solve.
When designing interventions at a small scale, we should consider zeros that hide in implementation details: facilitators who don't show up, curricula assuming knowledge students lack, and follow-up systems that break down. For scaled interventions, zeros appear in structural assumptions: assuming that algorithms will prioritize your content or distribution channels that miss your population entirely.
Finding and fixing these zeros matters more than optimizing other parts of your intervention.
In sum, the multiplicative nature of impact can be unforgiving.
Find Responsive Subjects
As the Hussam et al. paper suggests, behavioral change follows different response functions for different populations. Some groups are more receptive to the kind of intervention you are designing because they sit near the tipping points where even small pushes create significant shifts (e.g., giving money to high-ability entrepreneurs unlocks a fundamental constraint, while giving it to low-ability ones does not), while others are locked in stable equilibria that negate even large interventions.
This creates an optimization problem: given any budget, you maximize impact by targeting those with the steepest response gradients, the people ready to change. The principle applies whether you're going for depth or breadth.
Measure What Matters
Have a clear theory of change before you intervene: what mechanism will drive the outcome you care about? And, is this the outcome you care about?
Without this clarity, you cannot distinguish between interventions that work through your proposed mechanism versus those that create noise or move irrelevant proxies.
This requires specifying a clear “model” of the system you are trying to change. If you believe mentorship drives career advancement through skill development, then measure skill acquisition, not just meeting attendance.
When you measure outcomes aligned with your causal theory, you can create feedback loops that reveal whether your mechanism operates as theorized, allowing you to iterate based on evidence.
Push when Change is Cheaper
Most systems alternate between periods when change is cheap and periods when change is expensive.
Even small interventions during the “change is cheap” moments can shift entire trajectories. At the same time, the same effort during periods of stability (e.g., fighting the equilibrium) gets washed out without having an effect.
For individuals, these moments often occur during transitions, periods of uncertainty, or when motivation varies. The key to effective intervention design is recognizing the right time to push.
Moving the Needle
“Impact” is the word we use because we currently don’t have a better one for the idea that we want to do things that matter. In the end, what we care about is some combination of effect size and scale.
This shift in framing leads to some interesting questions, ones we can better wrestle with using existing frameworks from the social and statistical sciences.
What kind of effect am I trying to have? Do I want a big effect on a small number of people, or a smaller effect on a large group?
Once we see that there is often an inherent trade-off, it becomes more challenging to avoid “forcing” a choice.
This is because the things we must do to maximize effect size are often the very things that make scale harder, and vice versa. These are different problems, with different solutions.
It helps to be deliberate and thoughtful about these choices. Understanding the problem deeply and designing accordingly tends to yield better results than hoping something will work out.
We're all trying to make a difference in our own ways. Thinking with an experimental frame is just one approach that might help us be more intentional about the kinds of change we want to create, and more at peace with the tradeoffs we choose.
Here is another one for the nerds. General equilibrium effects. There's a more technical reason why scaling treatments might not work. Small-scale interventions operate without affecting market conditions, but scaled programs can become self-defeating. For instance, if everyone receives the same entrepreneurship training, markets flood with similar enterprises, destroying the very opportunities the training was meant to create.
Great piece, thanks for posting. I'm surely over-fixating on the trade-off figures, and i agree wholeheartedly with the point you make, but if the curve is convex in the shape you have it, isn't the optimal strategy to shoot for the point 45 degrees from the origin? ie to do both? The notion that shooting for both results in a muddled mess would be a concave curve, while simple 1:1 trade off would be a straight line. Or am i just reading these wrong?