
Superadditive #2: Bridging the Commercialization Gap: Researching and Teaching Deep Tech Innovation
Using machine learning to accelerate the search for commercially valuable science

What does it take to turn cutting-edge scientific discoveries into real-world products? A lot.
Today, I had the opportunity to teach a session in the Business of Science class offered through our Innovation and Entrepreneurship (I&E) initiative and taught by Doug Speight, the CEO of AxNano. We talked about some of the research on the deep tech innovation ecosystem and discussed how data and machine learning might reduce search frictions in the hunt for breakthroughs using Scientifiq.AI (a research platform Roger Masclans-Armengol, Wes Cohen, and I built here at Duke with the support of Duke, The Kauffman Foundation and NCBiotech). Here are my slides.
Deep Tech Research at Duke Strategy
Much of the research we discussed in class comes from work done by my colleagues here at Duke Strategy. Our Strategy Area faculty and PhD students (past and present) are some of the world’s leading experts on Deep Tech, technologies rooted in scientific and engineering breakthroughs.

For example, our faculty explores various aspects of the innovation ecosystem: Corporate Science (Sharon Belenzon), the Market for Technology (Ashish Arora), the Drivers of Firm Innovation (Wesley Cohen), America’s history of Corporate and Military Innovation (Daniel Gross), and Pharmaceutical Innovation in Orphan Diseases (David Ridley). The research also extends to policy and economic impact, such as work on the CHIPS Act and industrial policy (Ronnie Chatterji, formerly Chief Economist at Commerce and now at OpenAI).
More recent faculty additions further expand these themes: how firms find high-match, high-skilled workers and drive innovation (Ines Black), the impact of product sales skew on follow-on innovation (Yoko Shibuya), entrepreneurship in developing countries (Christopher Eaglin), and how firms collaborate to exchange knowledge and secrets (Evgenii Fadeev).
Even our recent students have contributed significant insights into the deep tech innovation ecosystem. The rise of corporate research (JK Suh, now at NYU-Stern), science and first-mover advantage (Bernardo Dionisi), firm interactions with the scientific commons (Dror Shvdron, now at U Toronto-Rotman), government procurement’s role in spurring innovation (Larisa Cioaca, heading to Tulane), commercialization capabilities of firms (Divya Sebastian, heading to ISB-Strategy), and assessing commercial potential (Roger Masclans) are just some of the areas they have explored. Even our early-stage students, including those at the beginning of their research journeys (William Miles, Hansen Zhang, and Jay Prakash Nagar), are also developing their research at the intersection of deep tech and innovation.1
Evolving Deep Tech Data Ecosystem
In addition to research illuminating the mechanisms driving innovation, there’s been a massive shift in how we study the role of science in business. A data revolution has created valuable public research tools. A few projects that have been incredibly helpful for my research with Wes Cohen and Roger Masclans — are Matt Marx’s incredible work on RelianceOnScience.org; these data have transformed innovation research (in fact, most of the students above have used data from here in one form or another); the second is the DISCERN data set put together by a team lead by Sharon Belenzon. These are just the tip of the iceberg: you should also check out the impressive i3 Innovation Data Index, a superstore of data infrastructure for innovation research.
Now that we’ve covered key research and data sources, let’s examine how these ideas translate to the Business of Science class.
The Business of Science

Looking around, it’s obvious that science (and “deep” technology) has fundamentally transformed human society. Science has touched nearly every aspect of our lives—our ability to recover from once-deadly or debilitating diseases, the security of our food, the fact that we can send information across the globe in the blink of an eye or call a self-driving car with our phone to take us from Fisherman’s Wharf to City Lights Bookstore in San Francisco. Deep tech will also be crucial in helping us tackle our most pressing challenges in climate and energy, as well as in harnessing fundamental physical forces to push the boundaries of computing—e.g., with quantum computing—in ways we never thought possible.
What is less obvious is that giving birth to these transformative technologies is incredibly hard and requires the alignment of at least three components: (a) money, and lots of it, to fund (b) “deep” research with uncertain outcomes that eventually get (c) commercialized into a product that generates revenue—that makes this all sustainable and work.
While there are historical examples of all three things being done “in-house” by a single corporation (e.g., think Bell Labs or DuPont), these components are often provisioned by distinct players from different sectors who have some overlapping interests but also many (many) conflicting motivations and incentives.
Given this complexity, the research on Deep Tech has convinced me that the conventional model of product development we might learn in business school (e.g., Minimum Viable Products, customer-driven innovation—design thinking, and a spray-and-pray funding strategy) is quite likely insufficient for innovating with this types of technologies.
This is the context of the Business of Science class: How do we innovate on the hard stuff?
The Division of Innovative Labor

The first idea I discussed in class is the Division of Innovative Labor (or DoIL), a concept I learned from my colleague Ashish Arora and his collaborators, including Alfonso Gambardella and Timothy Bresnahan.
So, what’s the idea? In a sense, DoIL recognizes that innovation isn’t usually done by one entity; instead, it results from collaboration between multiple actors in an ecosystem, such as firms, universities, venture capitalists, and governments. Each actor has distinct information and incentives and brings different capabilities to the table. Moreover, for these actors to collaborate effectively, they must have the absorptive capacity—the ability to acquire, assimilate, and apply external knowledge—and complementary capabilities so that everyone’s effort is super-additive.
Perhaps one of the most important recent papers on this topic is The Decline of Science in Corporate R&D by Arora, Belenzon, and Patacconi. What they document is quite striking: Corporations aren’t doing much “deep” science anymore, and this is true across a range of sectors (figures below from their paper).
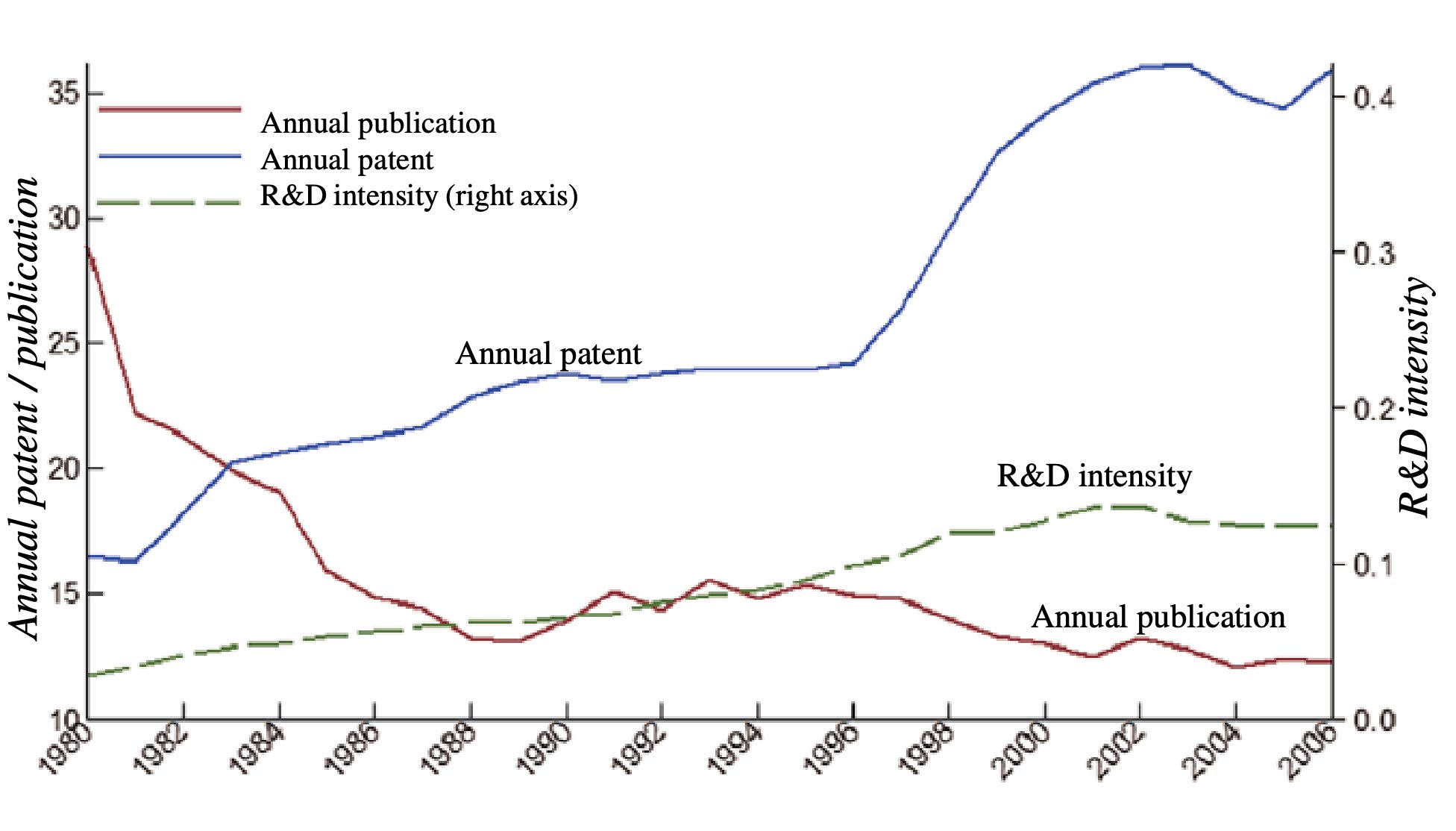
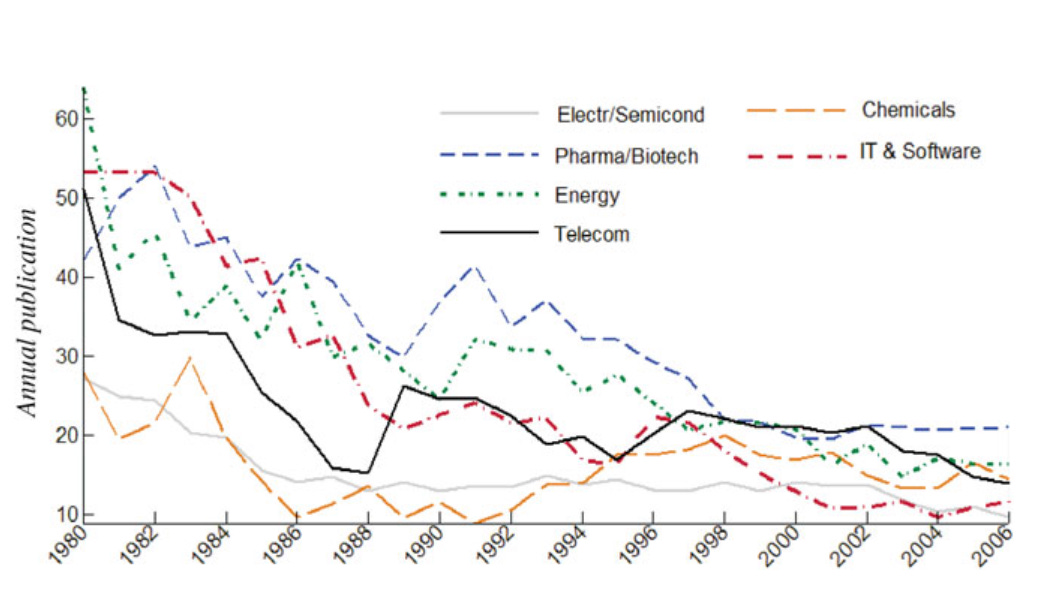
At the same time, the number of scientific publications produced by researchers has massively increased, not only in the United States but across the world—especially in China, but also in other countries. Here is some recent data from NSF.
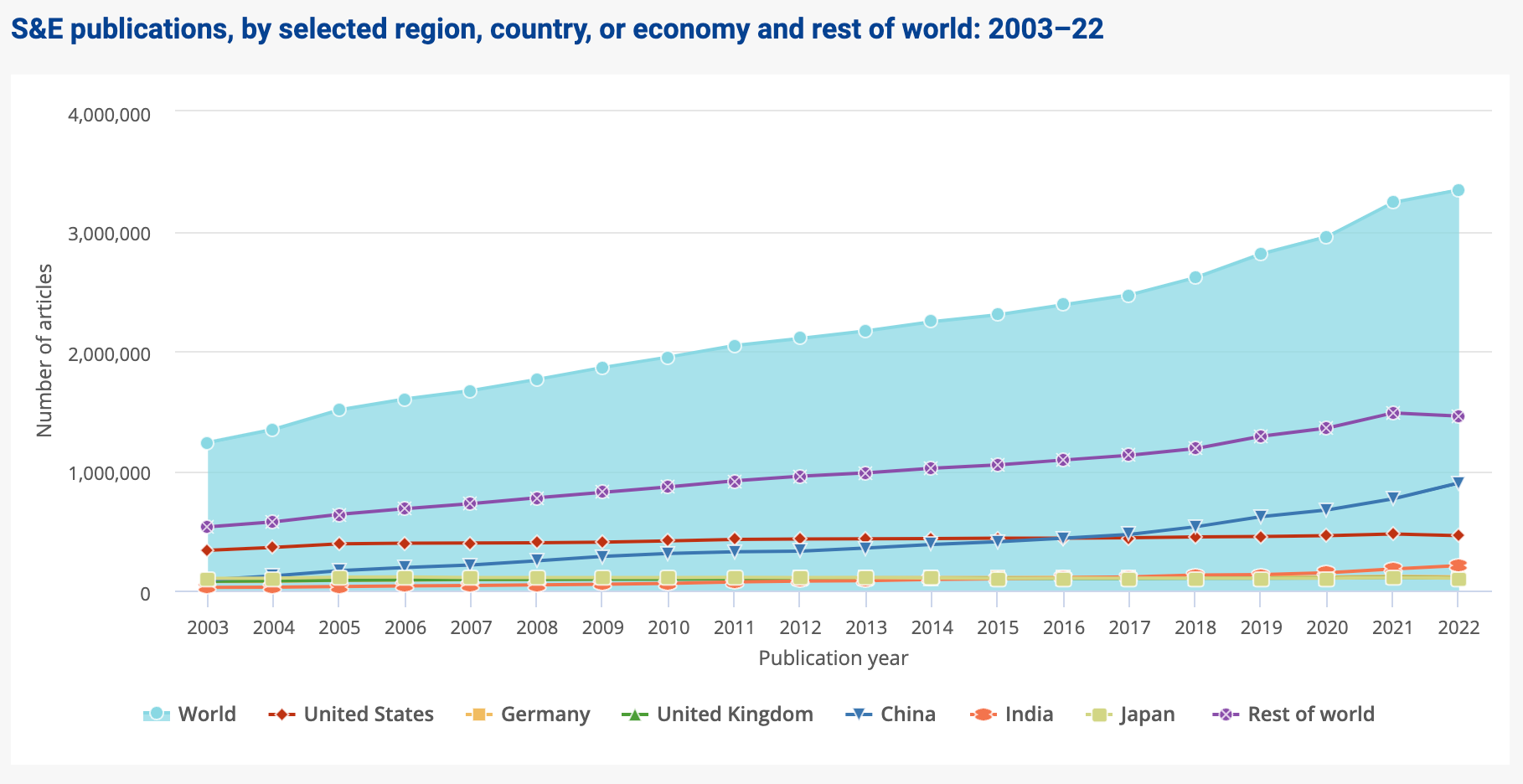
These two trends pose an interesting challenge: How do we bridge this gap? Science alone will not have an impact unless someone—a startup or a big company—decides to make follow-on investments to commercialize (e.g., develop and market) the ideas. Most scientific ideas alone aren’t enough to impact the world. Someone has to implement these ideas—and that is risky and expensive. Also, few companies do “deep” research themselves these days (though there are exceptions; the GenAI and quantum computing races are examples), and, as a result, firms need university research as part of their innovation system. Thus, one key challenge is informational: How do firms search for commercializable science in the ever-expanding ocean of global scientific research? It’s hard, even if we ignore the problem of incentives and capabilities.
How do firms find relevant commercializable research?
While the “search” problem faced by firms is quite complex, we might get some traction by simplifying the search into two dimensions: commercial potential and relevance.
Commercial Potential
Consider a major research university—where researchers produce thousands of scientific articles annually. For instance, Duke University researchers (according to the Web of Science) published 12,933 articles in 2023. Among these thousands of articles, some may represent scientific breakthroughs with no immediate commercial application, while others hold clear potential for firms seeking to innovate. The challenge for firms, however, lies in identifying which scientific discoveries are commercially valuable before they become widely recognized. That is, by the time a paper is widely cited (and easy to find on Google Scholar) or used by firms in their patents, it’s much too late. You need access to science early. Citations are lagging indicators—they tell you which research turned out to be valuable, not which research could be valuable. We are searching for hidden gems, not polished diamonds on sale at Tiffany’s.
How do we determine which of the 13,000 articles have high commercial potential ex-ante (or if you are searching globally— the 3 million articles published each year globally)?
In a recent NBER working paper titled Measuring the Commercial Potential of Science, Roger Masclans-Armengol, Wesley Cohen, and I introduce an approach to measuring scientific research's ex-ante commercial potential. The word potential is crucial, as it indicates the possible likelihood that something could be commercially useful—that is, we make predictions for an article just published (with “0” citations) about the likelihood that some firm will cite this article in their future patent and subsequently protect that patent further.
How do we do this? In essence, we pattern-match. We analyze tens of thousands of historical articles published at universities and identify patterns in their text that strongly predict future use by firms. Specifically, we use large language models (BERT) and neural networks to train a classifier using historical data. Then, we plug in the text of a recently published article and calculate an ex-ante measure predicting whether it is likely to be cited in a renewed patent—an indicator of its eventual commercial use.2
You can think of the commercial potential score we develop as an educated guess based on what the model has seen before about this article's eventual utility for a business. The score ranges from 0% to 100%, with anything over 70 indicating very high commercial potential.
After computing scores for all articles, we validated the predictions in various ways. Most amazingly, we used detailed data from a major technology transfer office with information on disclosure, investment, licensing, and revenue—all outcomes on which our model was never trained. Our model does quite well; see the binned scatter plot below for examples.3

Now that we have this measure of commercial potential, we can see which science produced at universities is actually used by firms. Not surprisingly, we found that firms tend to rely heavily on institutional reputation (actually, we see that much of the attention is directed towards super-star faculty) when sourcing scientific research, which might lead them to overlook commercially promising discoveries from less well-known universities or researchers. This “realization gap” suggests considerable potential in the science already out there—if firms could find it and assess its value or if universities knew what they were sitting on.

Commercial Relevance
We realized that our measure might also have some practical relevance. It could help firms, universities, governments, and even venture capitalists better assess which scientific research is likely to be useful to them.
However, to make the scores practically useful, we had to solve another problem: determining an article's or expert's Commercial Relevance. Given a specific scientific or product domain (e.g., trapped ion quantum computing), commercial relevance refers to the degree to which research, experts, or technological developments directly contribute to advancements, applications, or market potential within that domain.
Firms aren’t looking just for any science that has commercial potential. They are looking for science with commercial potential for the specific problem they are trying to solve. They are looking for relevance and potential, not just potential.

Finding relevant and high commercial potential researchers
Given there are thousands of universities, each with thousands of researchers, all producing work that is constantly changing. If someone asks, “Who’s working on quantum computing at Tsinghua University?”—how do you find out? Maybe you know someone, maybe you Google it. Now imagine trying to systematically identify every scientist whose work might be relevant to a firm—or, from the scientist’s perspective, every company that might find their work valuable.
This is a classic search problem. When the search space expands exponentially, organizations either develop better tools or rely on heuristics and shortcuts to simplify the search space. Historically, they’ve used the latter, leading to missed opportunities and inefficiencies.
Consider, for example, a few scientific topics that are commercially relevant:
Tissue engineering
Trapped-ion quantum computing
Digital Microfluidics
Computer vision
How do you efficiently find experts in these domains? This is already a challenging problem. It becomes even more difficult as you seek more specific science or try to find local experts in distant places.
Scientifiq.AI
Machine learning to accelerate the commercialization of frontier science.
It’s clear that bridging the gap between groundbreaking science and commercialization isn’t just an academic problem—it’s a society-wide challenge that leads to missed opportunities.
Many firms rely on outdated methods to search for scientific breakthroughs, often overlooking high-potential research because of institutional biases or inefficient discovery methods. This is why we took our research paper and built an experimental platform called Scientifiq.AI. We hope to make progress on the search problem using data and machine learning, hopefully helping universities, companies, and policymakers identify commercially relevant research faster and more accurately. Here’s how we think different types of people can use it.
For Universities: Find experts inside your university, and see what technology/science at your university firms might find useful.
For Companies: Discover relevant research, assess trends, and gain visibility into emerging technologies or scientific spaces.
For Policymakers & Investors: Track the commercial potential of scientific research and identify high-impact researchers to back.
For Researchers: Identify firms that may find your work valuable; see who is doing related research; and see how different topic areas where you are working are emerging.
Here is the front page of Scientifiq.AI.
Below, I’ll walk through a few features of Scientifiq.AI to get started.
1. The Search Page
How Scientifiq.AI Helps Solve This Problem
For researchers: Find firms that might commercialize your work.
For companies: Identify emerging technologies before they go mainstream.
For universities & policymakers: Track commercialization trends in specific areas and high-potential innovations at your university.
The search page is our primary interface in Scientifiq.AI.
For instance, I searched for tissue engineering and limited my search to documents with a “commercial signal” score of 45 or above (commercial signal is our fancier version of Commercial Potential—anything above 70 is relatively high) and for researchers and papers affiliated with MIT. Note that there are four tabs: Researchers (we have auto-generated profiles on millions of researchers across the world); Papers (updated weekly!); Patents (more on this in a different post); and Topics (summary pages about a scientific topic).
The results are sorted by RELEVANCE (people whose profile scores highest on “tissue engineering” regardless of commercial potential are ranked highest), and you can filter on the left by POTENTIAL (e.g., commercial signal) as well as scientific signal (the same idea as commercial potential, but trained with citations from academic papers, not firm patents). The keyword gets you relevance, and the sliding bars on the left get you potential. This puts you in the top RIGHT corner of the graph above.

The right names at MIT come up but feel free to try it for another university or another keyword (or a different country). For instance, tissue engineers in Canada, India, Brazil, or South Africa can be found by clicking the links.
2. The Researcher Profile
In the search results, you’ll see that every researcher has a card with a bunch of information on it:
Here is the card for Nenad Bursac, an expert on tissue engineering at Duke University. Scientifiq.AI autogenerates a biography for Dr. Bursac based on their most recent publications and uses our machine-learning algorithms to score every article associated with every researcher on the platform. The TOP designation means they are among the top 10 percent of all researchers worldwide on this score.

Once you click on the profile, you can see many more details: you can find out which firms have already leveraged their research into patents, which firms are working in adjacent technology spaces, and which universities hold related patents.

Scroll down some more, and you can see the author’s recent papers. There are also related patents (this is still an experimental feature—if you have ideas on how to improve it, we’ll take it!) and coolest of all, a recommender system to find other researchers working on similar topics.
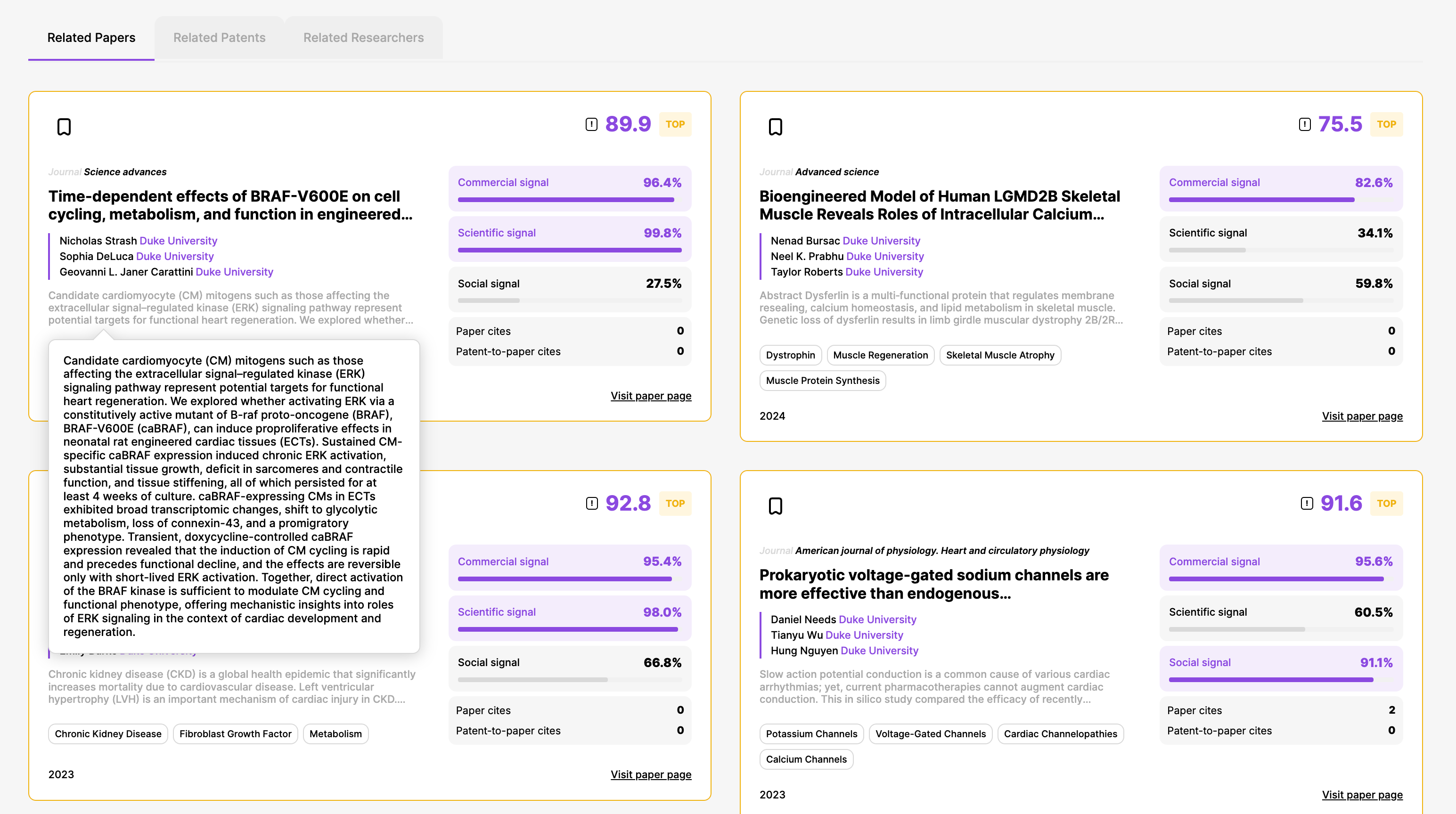
Here’s the screenshot of similar researchers page—other researchers who work on similar topics within tissue engineering to the main researcher whose page this is:

3. Find Researchers Anywhere in the World
Have you ever wondered who the experts on COVID-19 are in Mongolia? I have (well, not really, but I’m sure the Mongolian government has). With Scientifiq.AI, these researchers are a snap to find.
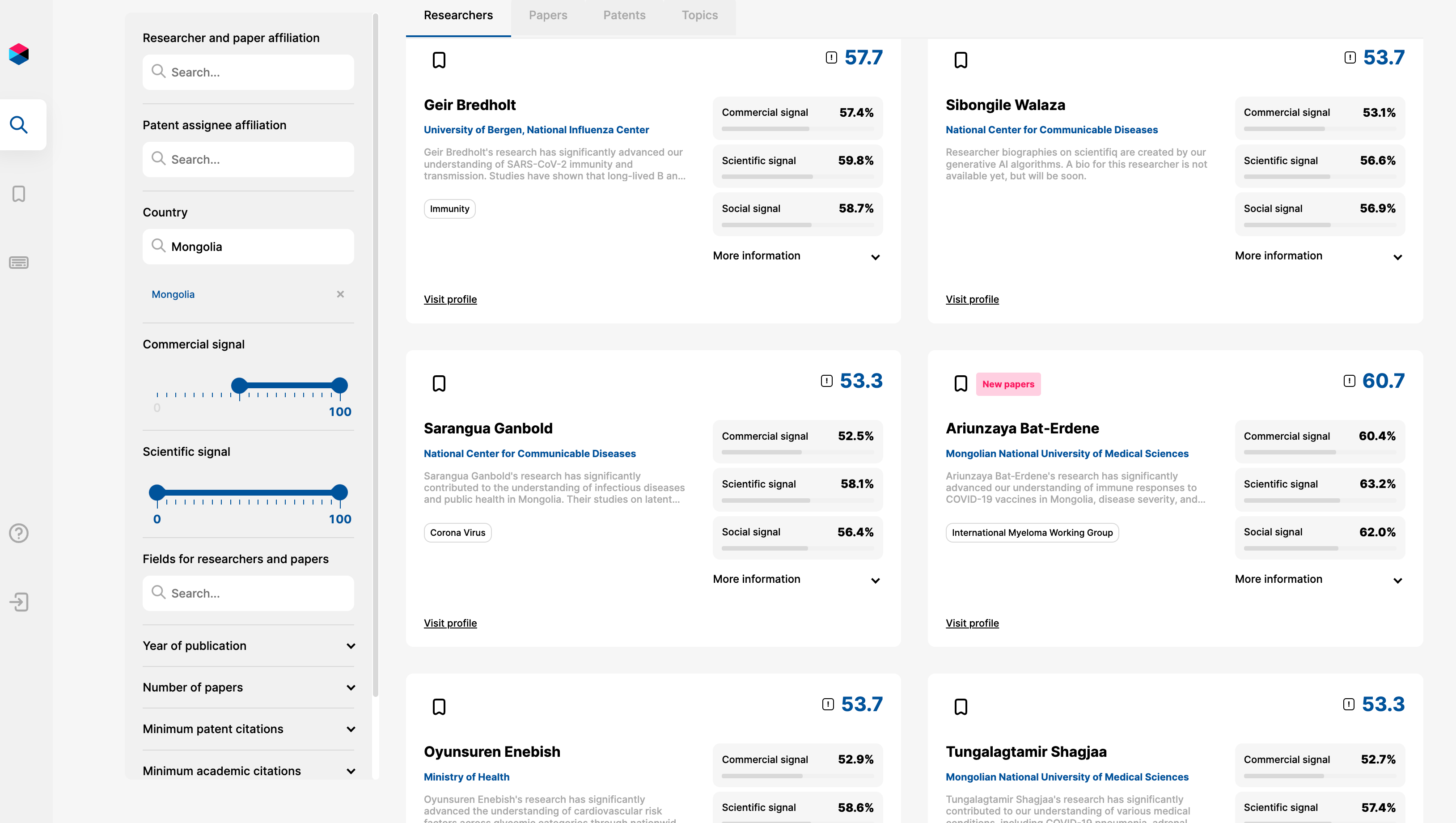
4. Topic Pages
Finally, maybe you want a birdseye view of Tissue Engineering — not just a deep dive into one researcher’s profile. Go back to the main search page and click Topics. There, you’ll find topics associated with the keyword “Tissue Engineering.” Here is the overall topic:

The topic page has lots of high-level info if you want to learn more about an area.
For instance, for the “Tissue engineering” topic, you get:
Overview – Introduction to tissue engineering, its significance, and medical applications.
Commercial Applications – Real-world uses in wound care, implants, organoids, biomaterials, and grafting.
Scientific Impact – Research influence, publication trends, and relevance across medical fields.
Latest Publications – Recent studies and key findings from top academic journals.
Top Papers (2022-2024) – Most influential research papers driving advancements.
Leading Researchers – Profiles of top contributors based on citations and publications.
Top Companies & Patents – Industry leaders, innovations, and key patents.
Leading Universities – Top institutions actively researching tissue engineering.
Related Topics – Connected fields like bioprinting, scaffold fabrication, and organ engineering.
Lot more features in Scientifiq.AI
There are a lot more features in Scientifiq.AI — but that’s for another day.
Remember to try Scientifiq.AI.
The End
OK, that’s it for today’s deep dive into the Business of Science. But we’ve only scratched the surface of how AI and data-driven approaches are transforming deep tech commercialization. If you’re curious to explore more, check out Scientifiq.AI—or let me know what challenges you see in bridging the gap between research and commercialization.
You’ll also notice that most articles are co-authored with a mix of multiple faculty and students.
We leverage data from RelianceOnScience to match articles to their patent citations.
Note: We’ve also made our data available for research in the spirit of open science. In the coming months, we hope to release worldwide data on the commercial potential of millions of papers.